Getting started with Looker
What is Looker, and why use it to analyze / visualize Snowplow data
Looker is a next-generation BI tool that is particularly well-suited to mining Snowplow data:
- It is architected to query the data stored in the database directly. (Rather than load it into its own in-memory engine.) That makes it ideally suited to exploring the very large data sets generated by Snowplow
- It is optimized to work with Amazon Redshift in particular
- It boasts a lightweight metadata model, that makes it easy for users with no SQL knowledge to perform very advanced queries against Snowplow data
For more information on why Looker plays so well with Snowplow data, see this blog post.
Setting up a Looker account
You can apply for a Looker account directly from the Looker website. Snowplow SaaS customers or users on our free trial can get in touch with the Snowplow team to request a Looker trial.
Connecting to Looker to Snowplow data in Redshift or PostgreSQL
This is a three step process:
- Create user credentials for Looker
- Add the server running Looker to your Redshift white-list (Redshift only)
- Add a connection from Looker to your Snowplowplow data in Redshift or PostgreSQL
Create user credentials for Looker
We recommend you create a dedicated 'Looker' user to access your Snowplow data. This user should have read only permissions on atomic.events, and write permissions on a new schema called looker_scratch, that Looker will use to persist temporary tables to. (Looker users temporary tables to make querying Snowplow data much faster.)
To do so, log into your Snowplow database using admin / super user credentials with your client of choice (e.g. Navicat, psql etc.) and execute the following:
CREATE USER looker PASSWORD {{ password }};
GRANT USAGE ON SCHEMA atomic TO looker;
GRANT SELECT ON atomic.events TO looker;
CREATE SCHEMA looker_scratch;
GRANT ALL ON SCHEMA looker_scratch TO looker;
Add the server running Looker to your Redshift white-list (Redshift only)
If you are using Amazon Redshift, you will need to add the server running Looker to one of your Redshift security groups.
To add the server:
- Log into the AWS Management console
- Select Redshift
- Select Security from left hand menu. A list of security groups will appear
- Select the security group you would like to add the server to. (Or create a dedicated one for the purpose.)
- Click on the security group and scroll down to the page bottom. You should see a dropdown for adding a new connection type (either CIDR/IP or EC2 Security Group)
- Select the appropriate option for the server running Looker. If this has been setup by either the Looker or Snowplow teams, then they will be able to provide the appropriate details
- If you've created a new security group just for Looker, you will need to add this to the Cluster. Select Clusters from the left hand menu, select your cluster and then click the Cluster dropdown at the top and select Modify. You should see a list of available security groups:
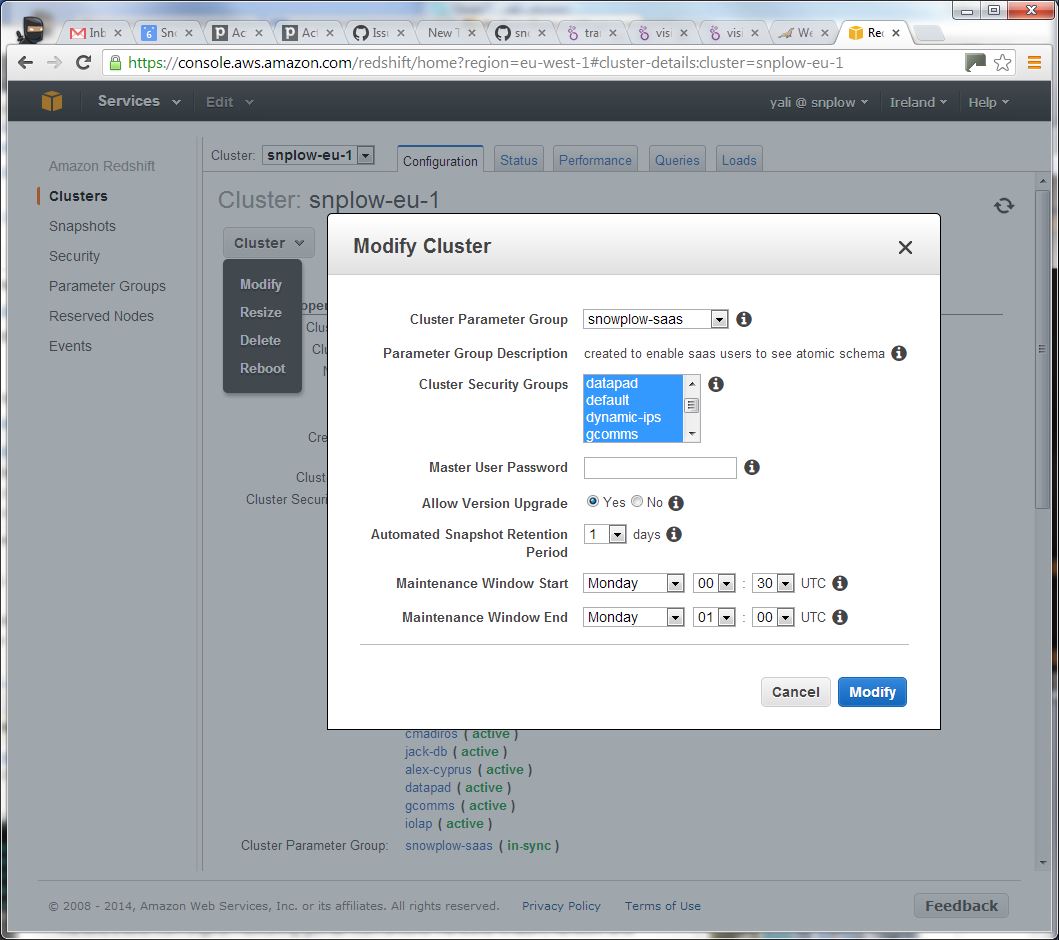
- Make sure you highlight your new security group then click the Modify button
- Looker should now be ready to access your data!
Add a connection from to your Snowplowplow data in Redshift or PostgreSQL
- Log into your Looker account
- Click on the admin link on the top right menu
- Click on the Connections link on the left hand menu (under Server Settings)
- Press the New Database Connection button (top right). The following screen appears:
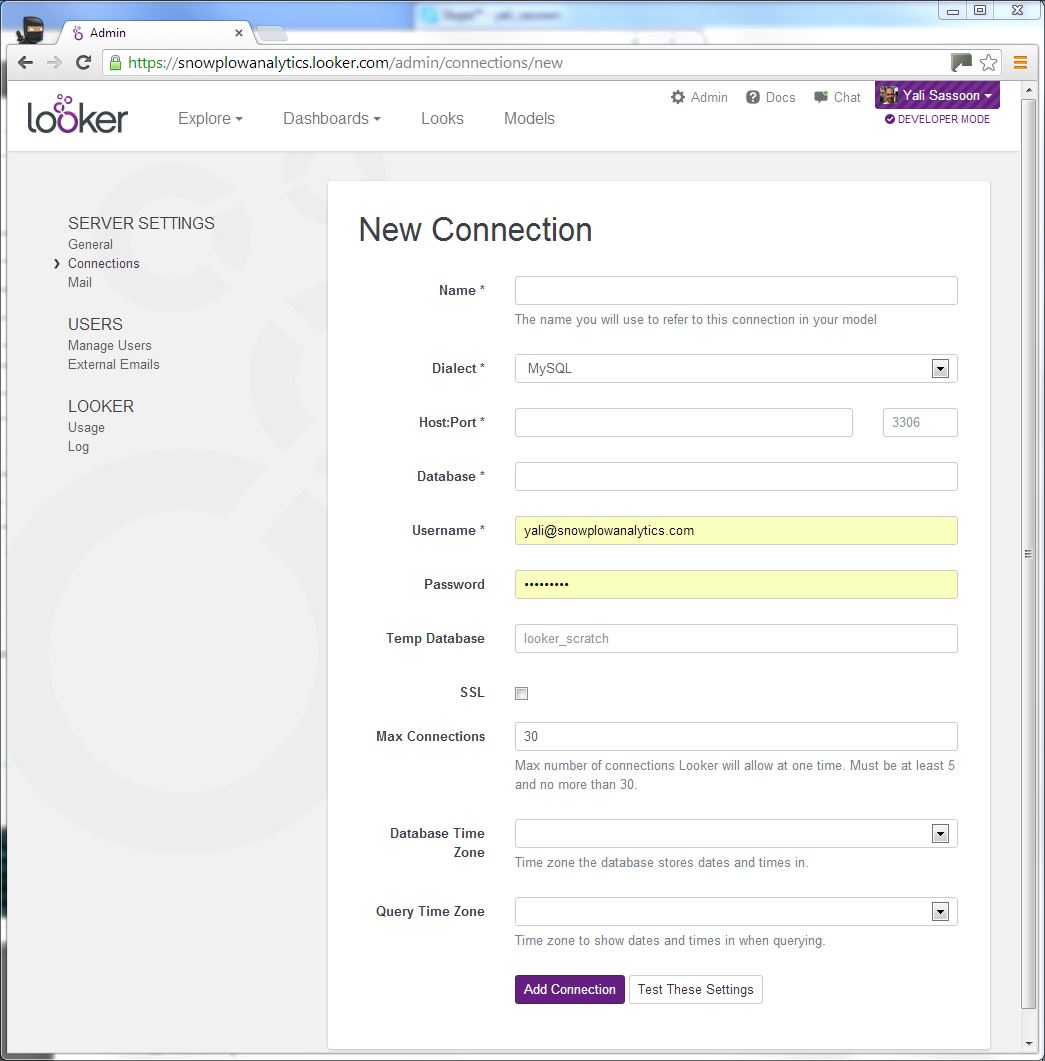
- Give your connection a name (e.g. "Snowplow")
- Select either
PostgeSQLorAmazon Redshiftfor the Dialect - Enter the host, port, database name, username and password you use to access your Snowplow data
- Enter
atomicfor Schema - Enter your connection details. (Including the username / password combination you setup in step 3.3 above.)
- Select Test These Settings. If they are working, press the Add Connection button.
- Looker can now access your Snowplow data!
Importing the metadata models
Note: if you are setting up a trial with the Looker or Snowplow teams, they should be able to set up the metadata models for you. If you want to go through the process yourself, however, follow these instructions:
- In the Looker UI, make sure you are in Developer Mode (by clicking on the Developer Mode icon on the top left under your username).
- Select Models on the top menu
- Select Generate New Model on the left hand menu under Tools
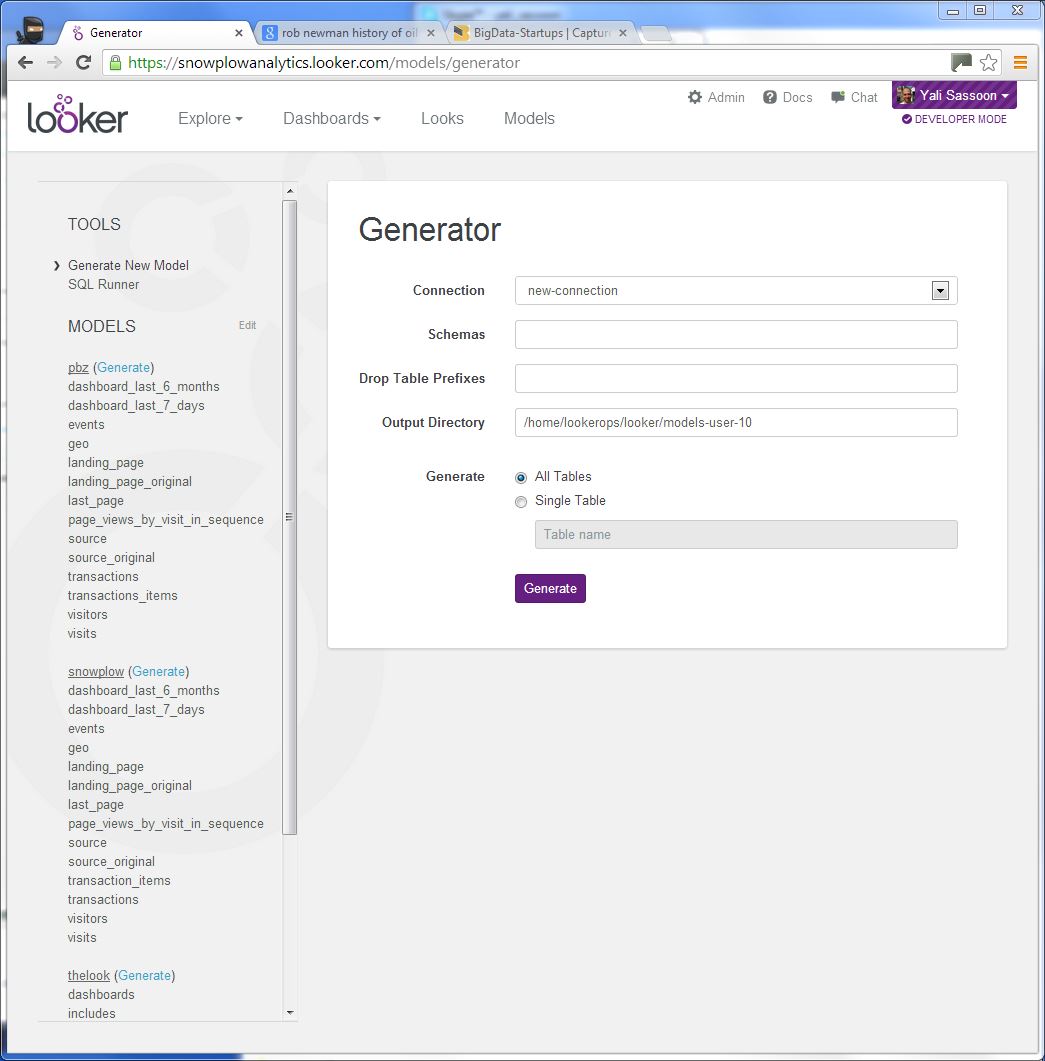
Select your connection from the dropdown. Enter 'atomic' under Schemas and click the generate button:
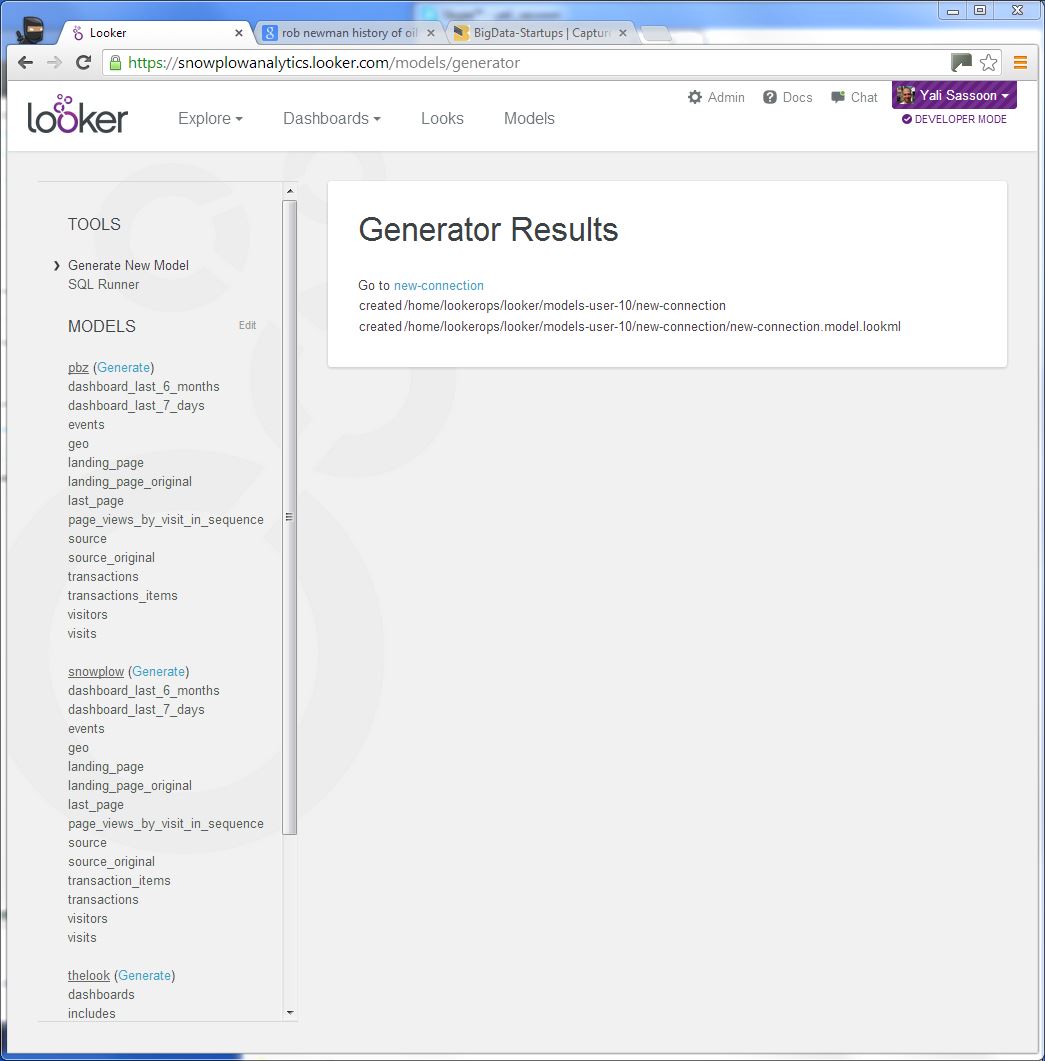
You will now see the new model stubbed in the left hand menu. (You may need to refresh the page.)
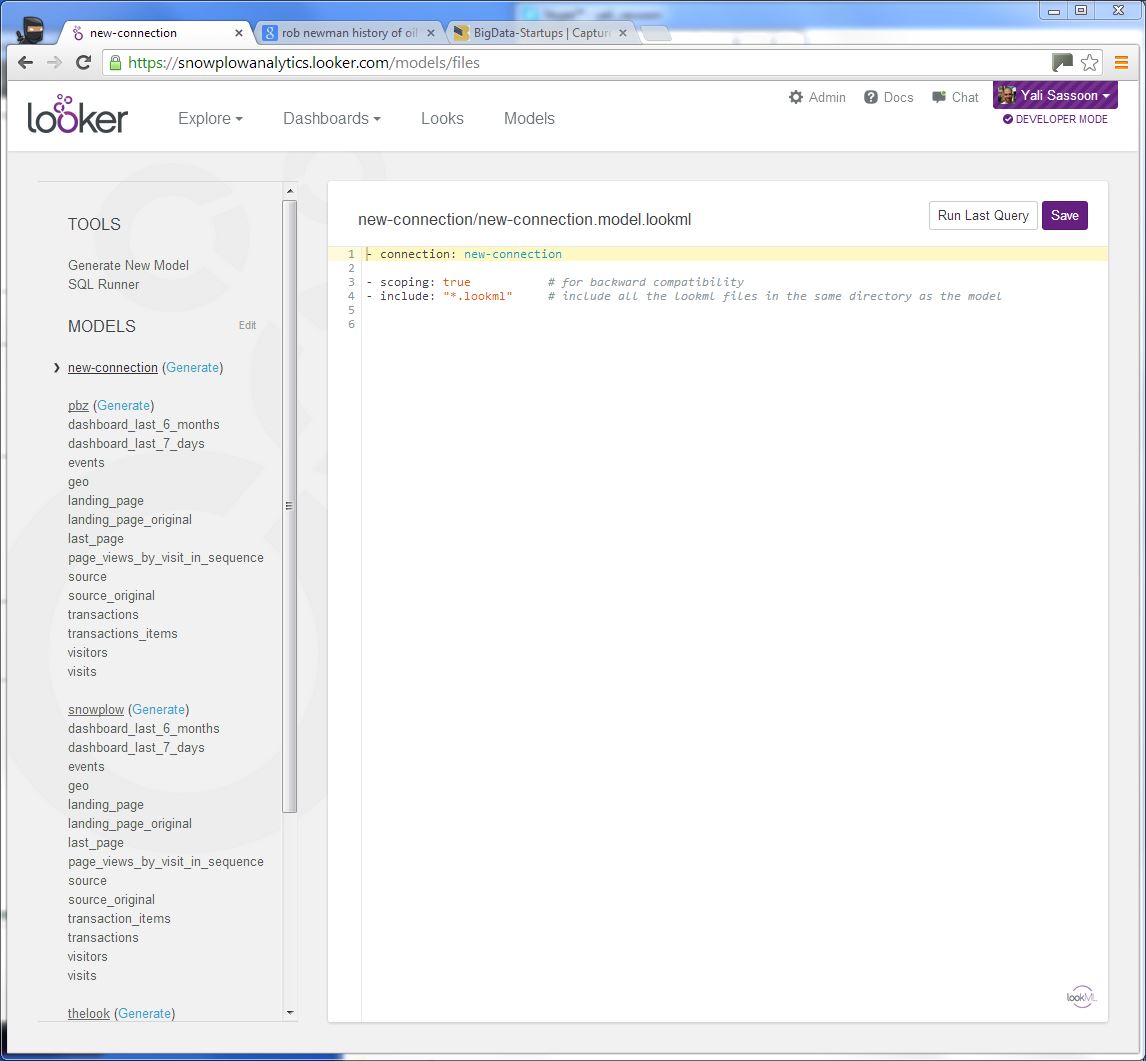
We now need to create a file for each of our models. Select the Edit link next to MODELS in the left-hand menu and then click the New File link (just below) to create a new file. Create the following files:
dashboard_last_6_monthsdashboard_last_7_dayseventsgeolanding_pagelanding_page_originallast_pagepage_views_by_visit_in_sequencesourcesource_originaltransactionstransactions_itemsvisitorsvisits
Then click the Done next to MODELS on the left hand menu.
Now we need to populate each of the models files. The YAML definitions to populate them can be found here, on our Github repo. Copy the contents of each file in the repo to the corresponding file in Looker.
You are now ready to explore your data in Looker!
Exploring your Snowplow data in Looker
Let's perform a simple analysis to start getting used to Looker. Let's analyze visitor and engagement levels by landing page.
Click on the Explore link in the top menu, select your connection and select Visits:
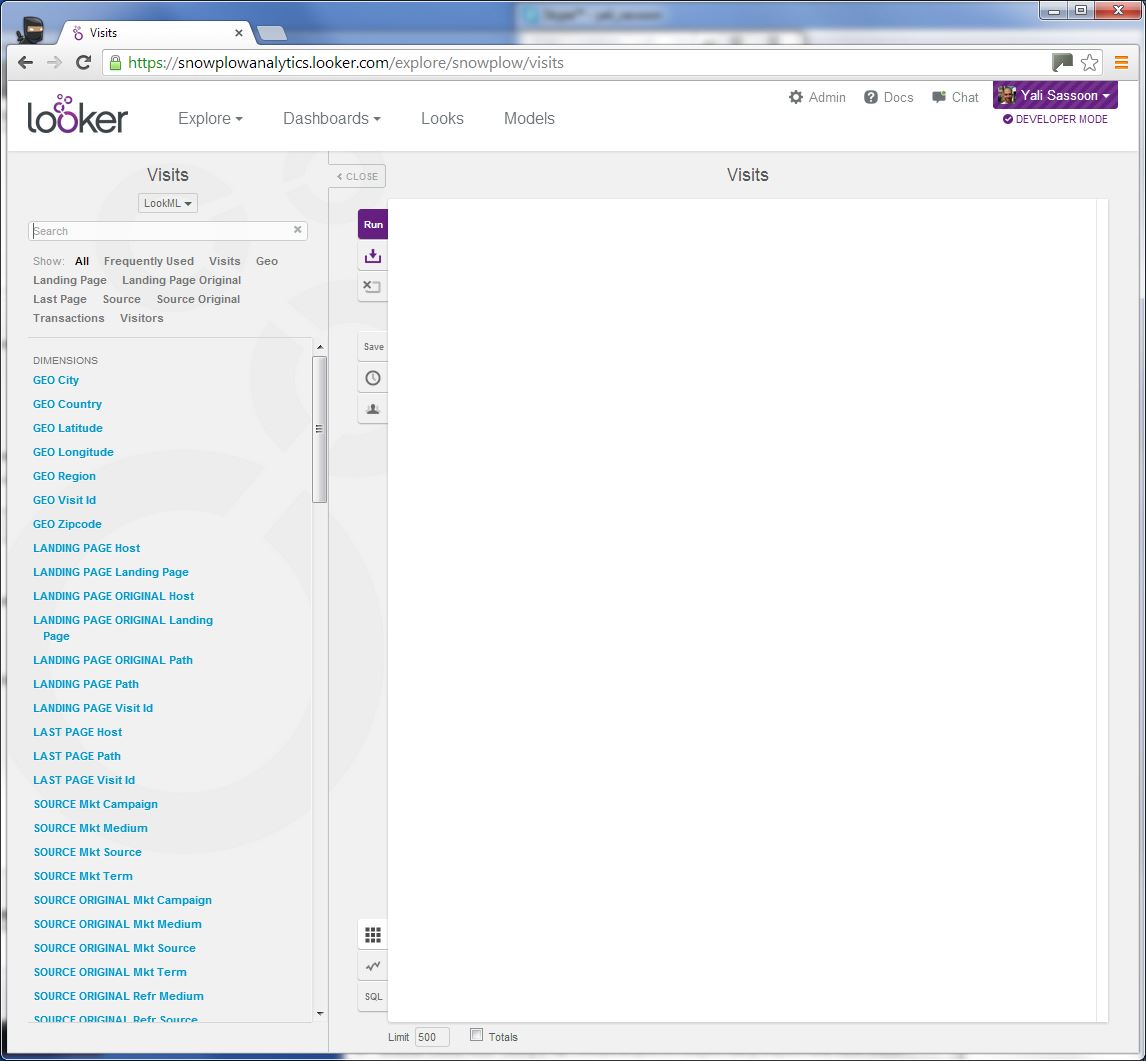
Select the following dimensions and metrics from the left hand list. (It may be easier to type them into the search box then scroll through the long list:
LANDING PAGE Landing pageVISITS Visit CountVISITS Events Per VisitVISITS Bounce Rate
Select the run button. You should see the three metrics given for each landing page:
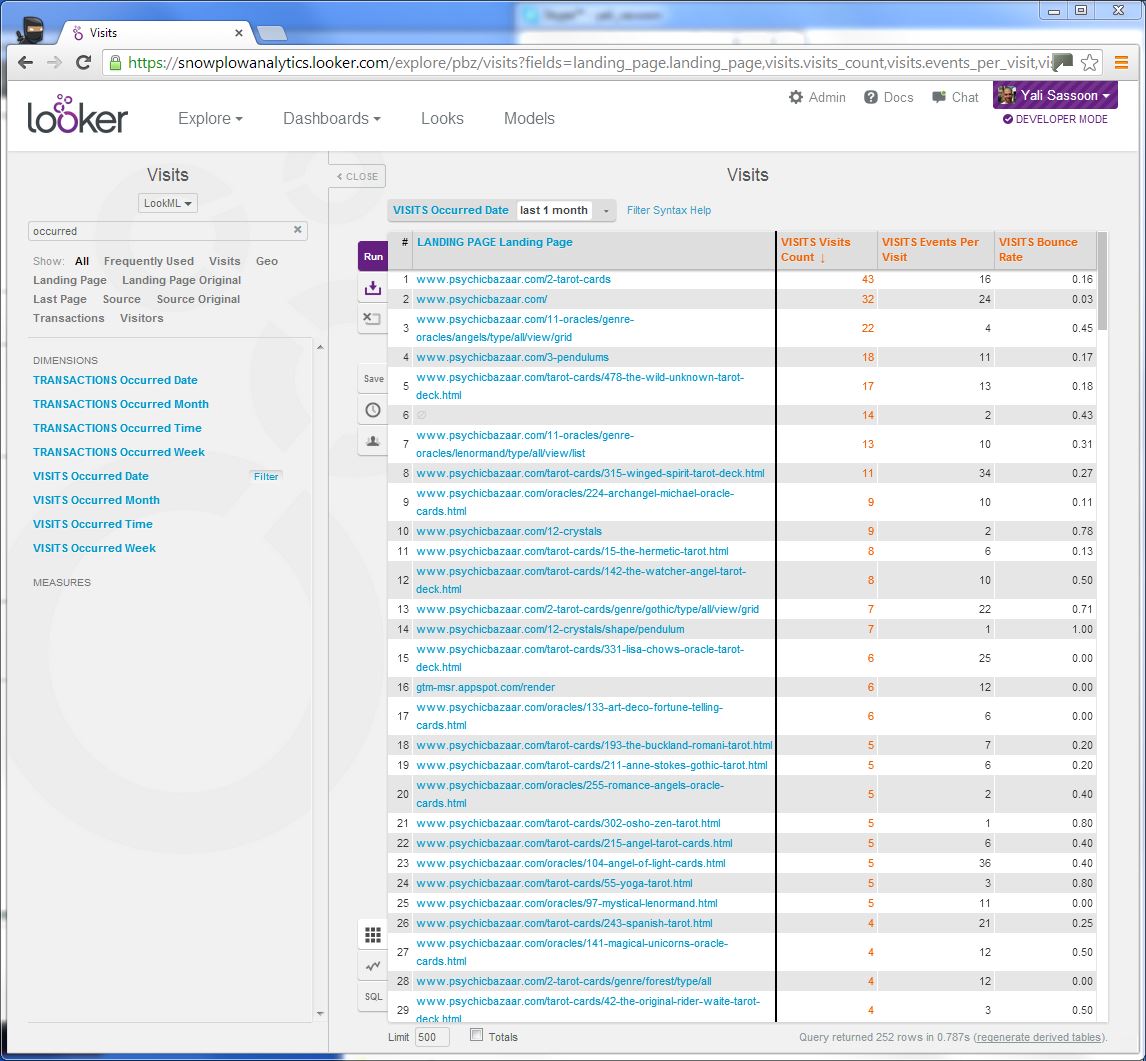
Easy - huh?