Querying failed events in Athena and BigQuery
Athena on AWS and BigQuery on GCP are tools that let you query your failed events, using the cloud storage files as a back-end data source.
SELECT data.failure.messages FROM adapter_failures
WHERE from_iso8601_timestamp(data.failure.timestamp) > timestamp '2020-04-01'
This approach is great for debugging your pipeline without the need to load your failed events into a separate database.
Before you can query this data, you need to create corresponding tables in Athena or BigQuery as we explain below. Each different failed event type (e.g. schema violations, adapter failures) has a different schema, so you will need one table per event type.
Creating the tables
- Athena
- BigQuery
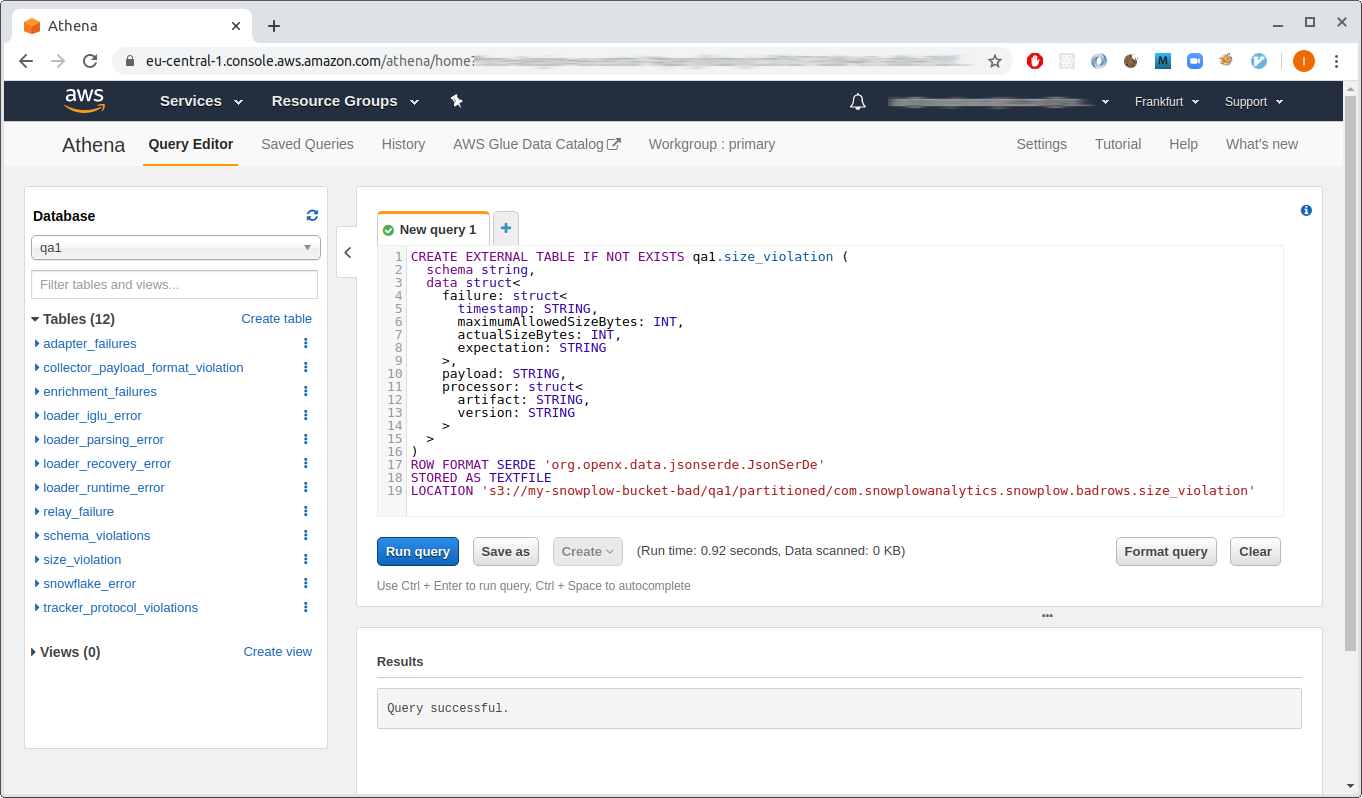
Go to the Athena dashboard and use the query editor. Start by creating a database (replace {{ DATABASE }} with the name of your pipeline, e.g. prod1 or qa1):
CREATE DATABASE IF NOT EXISTS {{ DATABASE }}
Then run each sql statement provided in the badrows-tables repository by copying them into the Athena query editor. We recommend creating all tables, although you can skip the ones you are not interested in.
Note that the sql statements contain a few placeholders which you will need to edit before you can create the tables:
{{ DATABASE }}— as above, change this to the name of your pipeline, e.g.prod1orqa1.s3://{{ BUCKET }}/{{ PIPELINE }}— this should point to the directory in S3 where your bad rows files are stored.
These instructions make use of the bq command-line tool which is packaged with the google cloud sdk. Follow the sdk instructions for how to initialize and authenticate the sdk. Also take a look at the BigQuery dashboard as you run these commands, so you can see your tables as you create them.
Create a dataset to contain your failed event tables:
bq mk --data_location=EU bad_rows_prod1
# Dataset 'my-snowplow-project:bad_rows_prod1' successfully created.
The --data-location should match the location of your bad rows bucket. Also replace prod1 with the name of your pipeline.
Next, download the table definitions provided in the badrows-tables repository in JSON format.
Each table definition contains a {{ BUCKET }} placeholder which needs to be changed to the GCS bucket where your bad rows files are stored (e.g. sp-storage-loader-bad-prod1-com_acme).
Now run bq mk for each table definition in turn. Use the --external_table_definition parameter so that BigQuery uses the bucket as the back-end data source. Here is how to run the command for the first three tables (note that you should change the dataset name bad_rows_prod1 to match the dataset you just created):
bq mk \
--display_name="Adapter failures" \
--external_table_definition=./adapter_failures.json \
bad_rows_prod1.adapter_failures
# Table 'my-snowplow-project:bad_rows_prod1.adapter_failures' successfully created.
bq mk \
--display_name "Schema violations" \
--external_table_definition=./schema_violations.json \
bad_rows_prod1.schema_violations
# Table 'my-snowplow-project:bad_rows_prod1.schema_violations' successfully created.
bq mk \
--display_name "Tracker protocol violations" \
--external_table_definition=./tracker_protocol_violations.json \
bad_rows_prod1.tracker_protocol_violations
# Table 'my-snowplow-project:bad_rows_prod1.tracker_protocol_violations' successfully created.
Run the corresponding commands for the remaining table definitions. We recommend creating all tables, although you can skip the ones you are not interested in.
BigQuery has an “Auto-detect” feature to automatically generate the table definition for you by inspecting the file contents. So you might wonder why it is necessary to provide explicit schema definitions for your tables.
There are two potential pitfalls when using the autogenerated schema with the Snowplow bad rows files:
- Optional fields. BigQuery might not “notice” that a field exists, depending on the sample of data used to detect the schema.
- Polymorphic fields, e.g.
errorthat can be either a string or an object. BigQuery will throw an exception if it sees an unexpected value for a field. Our table definitions use theJSONdata type for these fields.
Querying the data
- Athena
- BigQuery
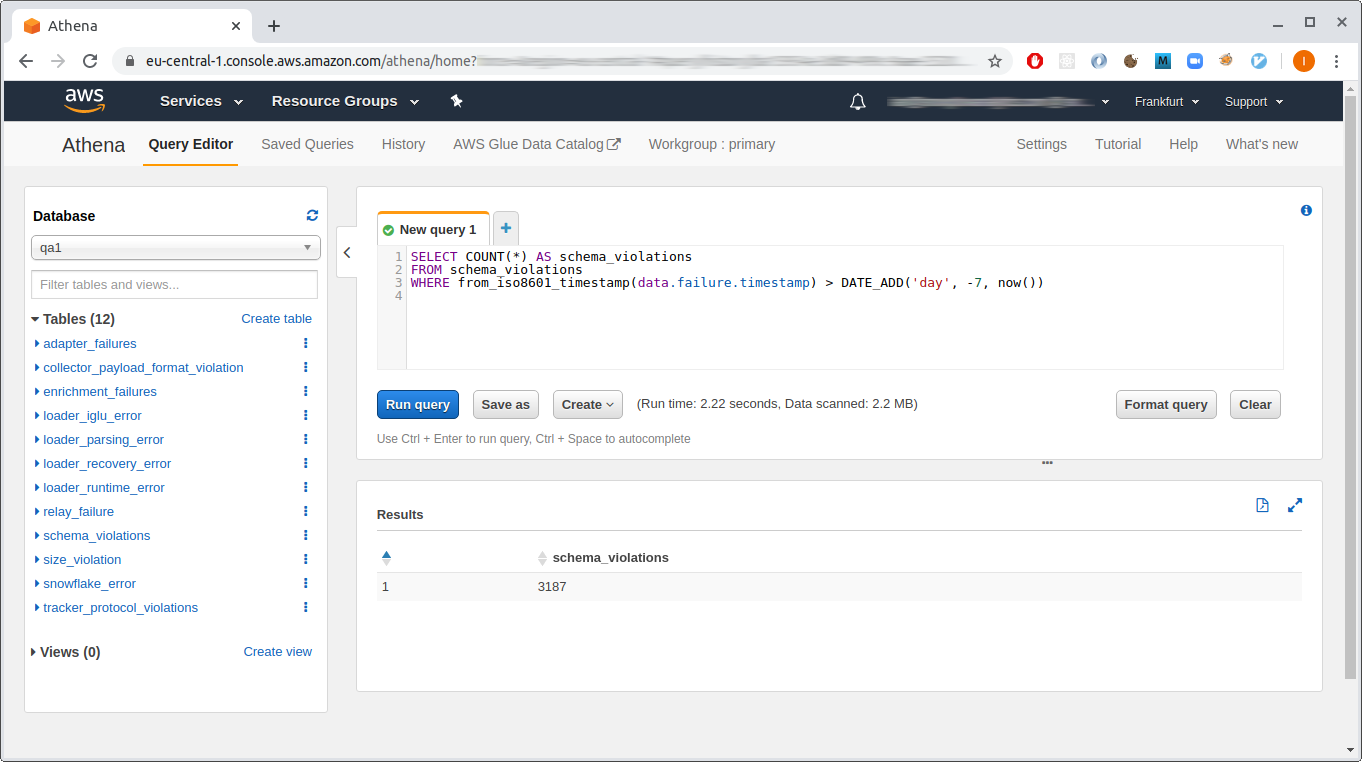
As example of using your Athena tables, you might start by getting counts of each failed event type from the last week. Repeat this query for each table you have created:
SELECT COUNT(*) FROM schema_violations
WHERE from_iso8601_timestamp(data.failure.timestamp) > DATE_ADD('day', -7, now())
If you have schema violations, you might want to find which tracker sent the event:
SELECT data.payload.enriched.app_id, COUNT(*) FROM schema_violations
WHERE from_iso8601_timestamp(data.failure.timestamp) > DATE_ADD('day', -7, now())
GROUP BY data.payload.enriched.app_id
You can do a deeper dive into the error messages to get a explanation of the last 10 failures:
SELECT message.field AS field,
message.value AS value,
message.error AS error,
message.json AS json,
message.schemaKey AS schemaKey,
message.schemaCriterion AS schemaCriterion
FROM schema_violations
CROSS JOIN UNNEST(data.failure.messages) AS t(message)
ORDER BY data.failure.timestamp DESC
LIMIT 10
You can query your tables from the query editor in the BigQuery console. You might want to start by getting counts of each failed event type from the last week. This query will work, but it is relatively expensive because it will scan all files in the schema_violations directory:
SELECT COUNT(*) FROM bad_rows_prod1.schema_violations
WHERE data.failure.timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY);
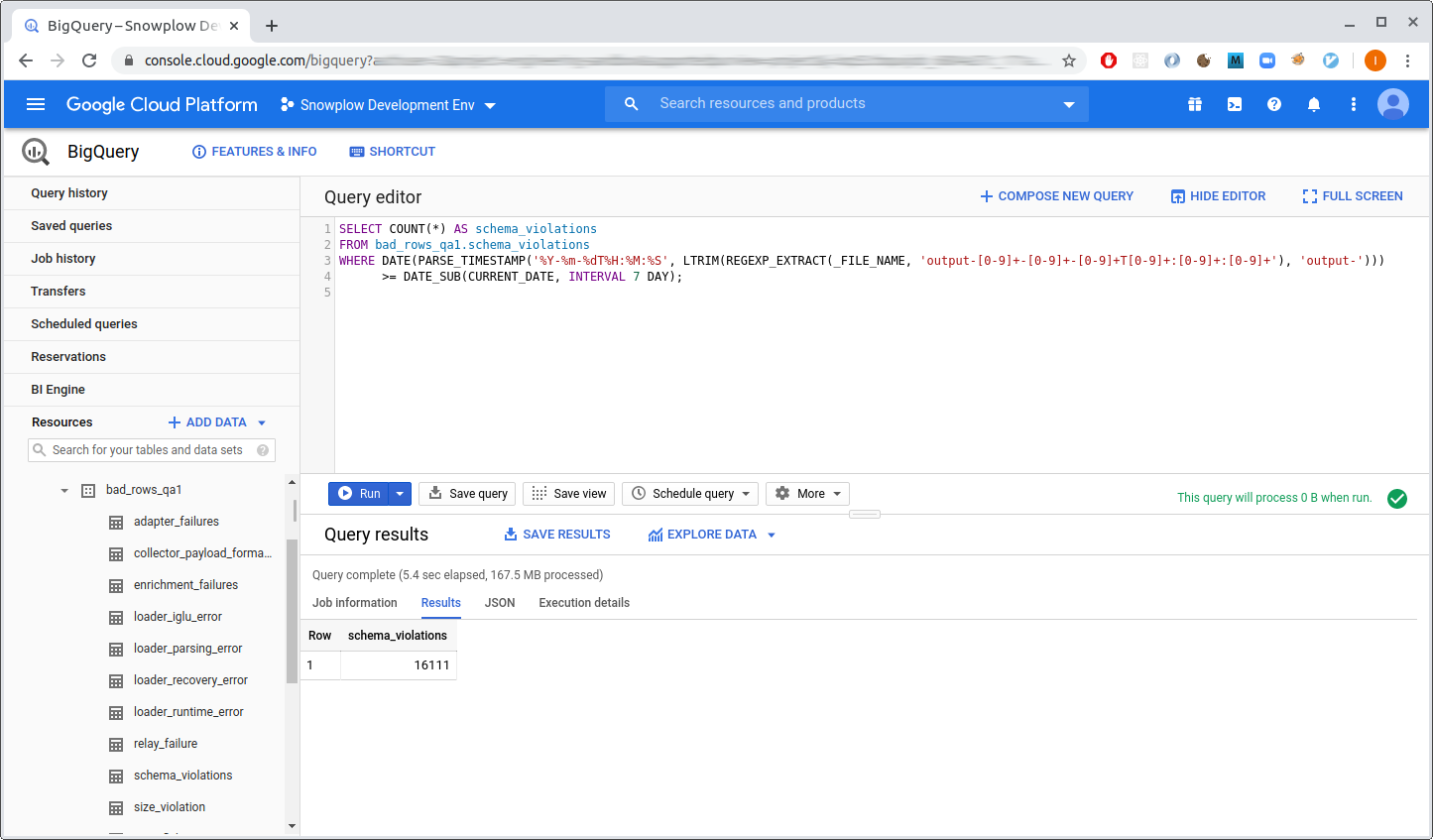
You can construct a more economical query by using the _FILE_NAME pseudo column to restrict the scan to files from the last week:
SELECT COUNT(*) FROM bad_rows_prod1.schema_violations
WHERE DATE(PARSE_TIMESTAMP('%Y-%m-%dT%H:%M:%S', LTRIM(REGEXP_EXTRACT(_FILE_NAME, 'output-[0-9]+-[0-9]+-[0-9]+T[0-9]+:[0-9]+:[0-9]+'), 'output-'))) >= DATE_SUB(CURRENT_DATE, INTERVAL 7 DAY);
You can repeat that query for each table you created in your bad rows dataset.
If you have schema violations, you might want to find which tracker sent the event:
SELECT data.payload.enriched.app_id, COUNT(*) FROM bad_rows_prod1.schema_violations
WHERE DATE(PARSE_TIMESTAMP('%Y-%m-%dT%H:%M:%S', LTRIM(REGEXP_EXTRACT(_FILE_NAME, 'output-[0-9]+-[0-9]+-[0-9]+T[0-9]+:[0-9]+:[0-9]+'), 'output-'))) >= DATE_SUB(CURRENT_DATE, INTERVAL 7 DAY)
GROUP BY data.payload.enriched.app_id;
If you have tracker protocol failures, you can do a deeper dive into the error messages to get a explanation of the last 10 failures:
SELECT message.field AS field,
message.value AS value,
message.error AS error,
message.expectation AS expectation,
message.schemaKey AS schemaKey,
message.schemaCriterion AS schemaCriterion
FROM bad_rows_prod1.tracker_protocol_violations,
UNNEST(data.failure.messages) AS message
WHERE DATE(PARSE_TIMESTAMP('%Y-%m-%dT%H:%M:%S', LTRIM(REGEXP_EXTRACT(_FILE_NAME, 'output-[0-9]+-[0-9]+-[0-9]+T[0-9]+:[0-9]+:[0-9]+'), 'output-'))) >= DATE_SUB(CURRENT_DATE, INTERVAL 7 DAY)
ORDER BY data.failure.timestamp DESC
LIMIT 10;
Digging deeper
You might notice that the error field in the result of the query above has the JSON type.
This is because depending on the variety of the failed event, the error might be a simple string or a complex object with additional detail.
For example, the “invalid JSON” message might have this error:
"invalid json: expected false got 'foo' (line 1, column 1)"
In contrast, in case of a failure to resolve Iglu server, the value in the error field would look like this, with “sub-errors” inside:
{
"error": "ResolutionError",
"lookupHistory": [
{
"attempts": 1,
"errors": [
{
"error": "RepoFailure",
"message": "Unexpected exception fetching: org.http4s.client.UnexpectedStatus: unexpected HTTP status: 404 Not Found"
}
],
"lastAttempt": "2021-10-16T17:20:52.626Z",
"repository": "Iglu Central"
},
...
]
}
You can figure out what to expect from such a field by looking at the JSON schema for the respective type of failed events, in this case the tracker protocol violations schema. The mapping between the various failed event tables and the corresponding JSON schemas is here.
BigQuery has a variety of JSON functions that allow you to extract data from within complex objects. For instance, if you are interested in Iglu repositories that failed to resolve, you can use something like this:
SELECT DISTINCT(JSON_VALUE(message.error.lookupHistory[0].repository))
FROM ...
WHERE ...
AND message.error.lookupHistory IS NOT NULL
It’s also possible, although unwieldy, to reduce all errors to a single string:
-- Unnest individual messages for each failed event
WITH unnested_messages AS (
SELECT message, CASE
-- resolution errors
WHEN message.error.lookupHistory IS NOT NULL THEN JSON_QUERY_ARRAY(message.error.lookupHistory[0].errors)
-- event validation errors
WHEN message.error.dataReports IS NOT NULL THEN JSON_QUERY_ARRAY(message.error.dataReports)
-- schema validation errors
WHEN message.error.schemaIssues IS NOT NULL THEN JSON_QUERY_ARRAY(message.error.schemaIssues)
-- other errors
ELSE [TO_JSON(STRUCT(message.error as message))]
END AS errors
FROM bad_rows_prod1.tracker_protocol_violations,
UNNEST(data.failure.messages) AS message
WHERE ...)
SELECT JSON_VALUE(error.message) AS error
FROM unnested_messages,
UNNEST(errors) AS error
In the future, we plan to simplify the schemas of failed events so that they are more uniform and straightforward to query.