RDB Loader (Redshift, Snowflake, Databricks)
We use the name RDB Loader (from "relational database") for a set of applications that can be used to load Snowplow events into a data warehouse. Use these tools if you want to load into Redshift, Snowflake or Databricks. For other destinations, see here.
Loading enriched Snowplow data is a two-step process which consists of:
- transforming the enriched tsv-formatted data into a format that can be readily loaded into a target (previously known as 'shredding');
- loading the transformed data.
Each step is handled by a dedicated application: transformer or loader. To load Snowplow data with RDB Loader, you'll need to run one of each.
For more information on how events are stored in the warehouse, check the mapping between Snowplow schemas and the corresponding warehouse column types.
How to pick a transformer
The transformer app currently comes in two flavours: a Spark job that processes data in batches, and a long-running streaming app.
The process of transforming the data is not dependent on the storage target. Which one is best for your use case depends on three factors:
- cloud provider you want to use (AWS or GCP)
- your expected data volume
- how much importance you place on deduplicating the data before loading it into the data warehouse.
Based on cloud provider
If you want to run the transformer on AWS, you can use Spark transformer (snowplow-transformer-batch) or Transformer Kinesis (snowplow-transformer-kinesis).
If you want to run the transformer on GCP, you can use Transformer Pubsub (snowplow-transformer-pubsub).
Based on expected data volume
The Spark transformer (snowplow-transformer-batch) is the best choice for big volumes, as the work can be split across multiple workers. However, the need to run it on EMR creates some overhead that is not justified for low-volume pipelines.
The stream transformer (snowplow-transformer-kinesis and snowplow-transformer-pubsub) is a much leaner alternative and suggested for use with low volumes that can be comfortably processed on a single node. However, multiple stream transformers can be run parallel therefore it is possible to process big data volume with stream transformer too.
To make the best choice, consider:
- What is the underlying infrastructure? For example, a single-node stream transformer will perform differently based on the resources it is given by the machine it runs on.
- What is the frequency for processing data? For example, even in a low-volume pipeline, if you only run the transform job once a day, the accumulated data might be enough to justify the use of Spark.
Based on the importance of deduplication
The transformer is also in charge of deduplicating the data. Currently, only the Spark transformer can do that.
If duplicates are not a concern, or if you are happy to deal with them after the data has been loaded in the warehouse, then pick a transformer based on your expected volume (see above). Otherwise, use the Spark transformer.
How to pick a loader based on the destination
There are different loader applications depending on the storage target. Currently, RDB Loader supports Redshift, Snowflake and Databricks.
For loading into Redshift, use the snowplow-rdb-loader-redshift artifact.
For loading into Snowflake, use the snowplow-rdb-loader-snowflake artifact.
For loading into Databricks, use the snowplow-rdb-loader-databricks artifact.
AWS is fully supported for both Snowflake and Databricks. GCP is supported for Snowflake (since 5.0.0.).
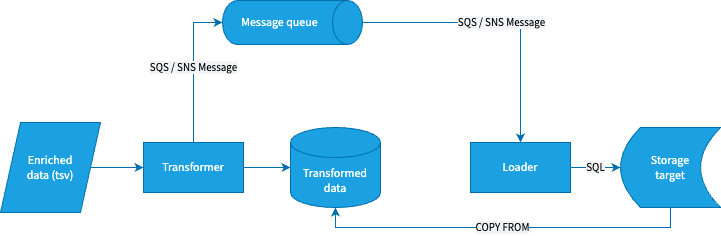
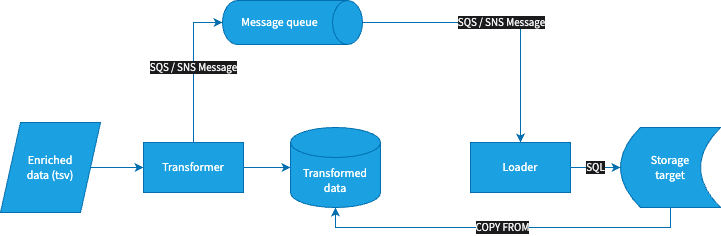
How transformer and loader interface with other Snowplow components and each other
The applications communicate through messages.
The transformer consumes enriched tsv-formatted Snowplow events from S3 (AWS) or stream (AWS and GCP). It writes its output to blob storage (S3 or GCS). Once it's finished processing a batch of data, it issues a message with details about the run.
The loader consumes a stream of these messages and uses them to determine what data needs to be loaded. It issues the necessary SQL commands to the storage target.